Recently, a text-to-speech project named ChatTTS goes viral and has garnered 28k stars on GitHub. Designed specifically for dialogue scenarios, this speech generation model supports both English and Chinese languages. It has been optimized for conversational tasks, achieving natural and fluent speech synthesis.
 from https://chattts.com/
from https://chattts.com/
Highlights of ChatTTS
Dialog-based TTS: ChatTTS is optimized for dialog-based tasks, achieving natural and fluent speech synthesis, while also supporting multiple speakers.
Fine-grained control: The model can predict and control fine-grained prosodic features, including laughter, pauses, and filler words, among others.
Better prosody: ChatTTS surpasses most open-source text-to-speech (TTS) models in terms of prosody, being able to incorporate laughter or change intonation while speaking, making conversations more natural.
How to take ChatTTS to the next level
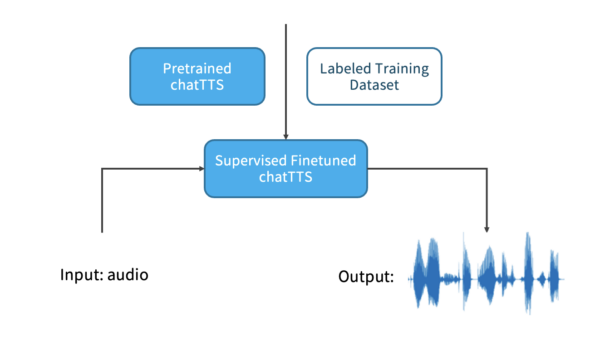
The performance of ChatTTS is already excellent, and developers can further enhance its capabilities on this basis through SFT (Supervised Fine-Tuning).
SFT is a technique that further optimizes a pre-trained large model using labeled data. This method leverages the pre-trained model’s learning capabilities on large-scale unsupervised data and adjusts it with labeled data, making it more suitable for specific task requirements.
– By fine-tuning with labeled data that includes the specific timbre of a speaker, the model can generate speech with the desired timbre.
– The inference speed can be improved by optimizing the model structure and using efficient algorithms, making it suitable for real-time scenarios.
– Further enhancement of the adaptation to punctuation and special characters can be achieved by fine-tuning with corpora that include a rich set of punctuation marks and special characters. Additionally, fine-tuning with strictly annotated dialogue data can help avoid omissions or repetitions, improving the stability of the content generated by the model.
– The ability to maintain consistent timbre across different texts can be enhanced by fine-tuning with a more consistent audio dataset.
By implementing these SFT and high-quality data measures, the overall performance and user experience of ChatTTS can be further improved.
Dataocean AI’s Thousand-Person Multilingual Speech Synthesis Dataset
In the field of TTS, the quality of data is crucial. Especially during the SFT process, high-quality labeled speech synthesis dataset is one of the key factors that determine the performance and quality of the model, and only high-quality data can better enhance the performance of the voice synthesis system.
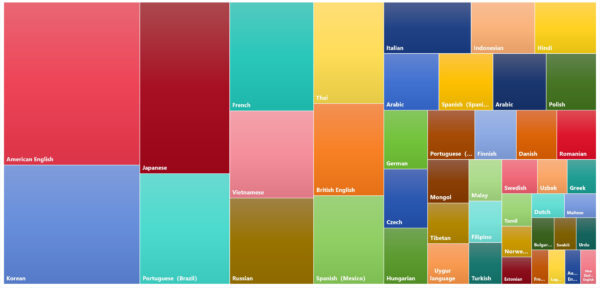
Dataocean AI has a high-quality labeled speech synthesis dataset in multiple languages from over 40 countries and regions, including Arabic, German, French, Russian, Japanese, Korean, Portuguese, Spanish, Italian, Dutch, Finnish, Danish, Swedish, Norwegian, Czech, Polish, Vietnamese, Mongolian, and more. It includes 1300 speakers, with a total duration of 1343 hours, and a balanced gender ratio. The topics covered are extensive, including everyday spoken language, news, work, social interactions, music, family, health, travel, weather, etc. In addition, it supports multiple timbres, styles, and emotions, allowing the model to cover a wide range of content expression and usage scenarios, making it more natural and closer to real human expression.
High-standard Collection Environment Ensures Top-notch Audio Quality
To provide higher quality voice data, the voice collection process of Dataocean AI adheres to strict standards to ensure the recording quality. Through high-standard equipment configuration and recording environment, the high quality of speech synthesis data is ensured, providing a solid foundation for creating a natural, smooth, and high-fidelity speech synthesis system.

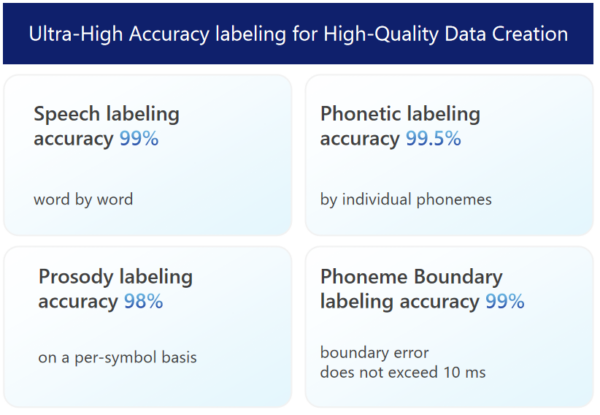
Ultra-High Accuracy Labeling for High-Quality Data Creation
Dataocean AI ‘s speech synthesis data includes high-precision labeled speech data and corresponding text data, with detailed annotations of pronunciation details. Furthermore, Dataocean AI utilizes the leading DOTS platform for data preprocessing and combines it with expert manual verification to further enhance the accuracy of speech synthesis data.