




OpenVoice is a versatile instant voice cloning method that requires only a short audio clip from the reference speaker to replicate their voice and generate speech in multiple languages. This technology marks a significant advancement in solving open challenges in the field, including:
Flexible Voice Style Control: OpenVoice allows for fine control over various voice styles, such as emotion, accent, rhythm, pauses, and intonation, while also replicating the tone color of the reference speaker. Unlike previous methods, voice styles are not strictly copied from the reference speaker and are not constrained by them, allowing for more flexible manipulation of voice styles after cloning.
Zero-Shot Cross-Lingual Voice Cloning: OpenVoice achieves zero-shot cross-lingual voice cloning for languages not covered in the massive-speaker training set. This differs from earlier methods, which typically require extensive massive-speaker multi-lingual (MSML) datasets for all languages. OpenVoice can clone voices into a new language without needing massive-speaker training data for that language. Additionally, it is computationally efficient, costing significantly less than commercially available APIs with comparatively inferior performance.
To support further research, the source code and trained model have been made publicly accessible. Qualitative results are also available on the demo website. Before its public release, OpenVoice’s internal version was used tens of millions of times by users worldwide from May to October 2023, serving as the backend of MyShell.ai.
Overview
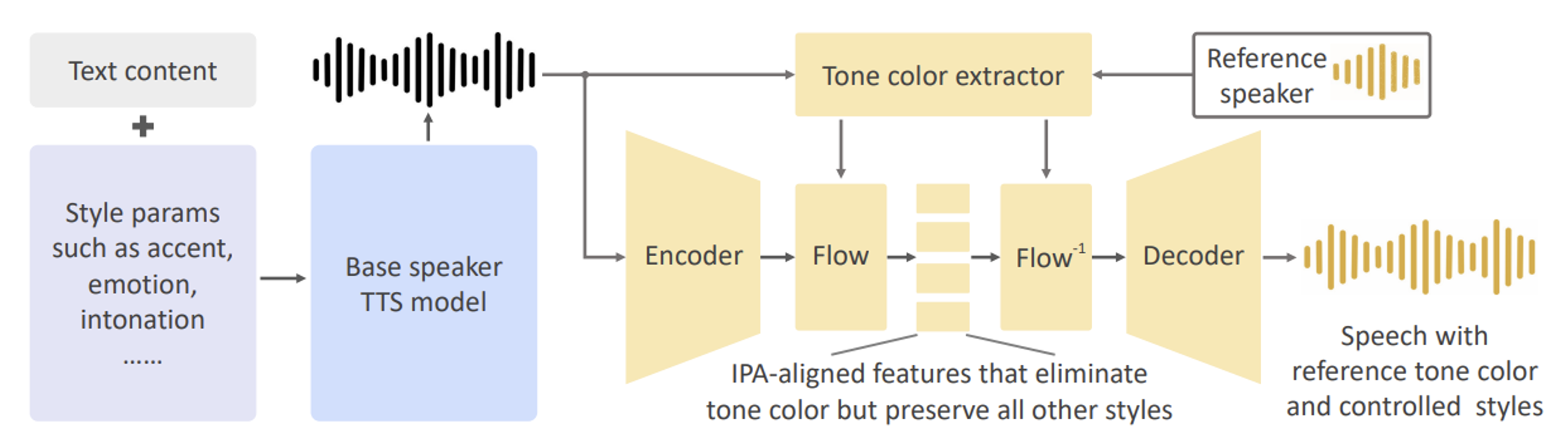
From”OpenVoice: Versatile Instant Voice Cloning”
The above figure shows the framework of OpenVoice, which includes two key parts: the base speaker TTS model and the tone color converter. The base speaker TTS model can function as a single or multi-speaker system, managing style parameters such as emotion, accent, rhythm, and language. Its output undergoes tone color conversion to match the reference speaker. The base speaker TTS model is versatile, compatible with various models like VITS and InstructTTS, and even commercial options like Microsoft TTS. It’s possible to bypass this model and input speech directly in any style or language. OpenVoice typically uses the VITS model, but other options are also viable. The model’s output, denoted as X(L_I, S_I, C_I), represents language, style, and tone color.
The tone color converter is an encoder-decoder with a central normalizing flow, processing the output of the base model. It uses a 1D CNN encoder and a 2D CNN tone color extractor to convert the input into a feature vector encoding tone color. The normalizing flow layers then remove the tone color, aligning the remaining features with the International Phonetic Alphabet. This processed output is then combined with the tone color of the reference speaker and ultimately decoded into waveforms by HiFi-Gan.
Although there are other methods for feature extraction, OpenVoice’s approach ensures superior audio quality. Some methods may lose subtle differences in emotion and accent, or struggle with unfamiliar languages.
The novelty of OpenVoice lies in its decoupled framework, separating voice style and language control from tone color cloning. This simplicity enhances the diversity of styles and languages without the need for extensive data and computing resources. Its core philosophy is to separate the generation of voice style and language from tone color production, ensuring fluency and adaptability. The experimental section further discusses the use of flow layers in the tone color converter and the importance of a universal phoneme system for language generalization.
Datasets
To develop a basic Text-to-Speech (TTS) synthesis model, OpenVoice collected audio samples featuring American English, British English, Chinese, and Japanese accents. These samples comprise a total of 30,000 sentences, with an average duration of 7 seconds per sentence. The English and Chinese samples include emotion labels.

OpenVoice modified the VITS model by incorporating emotion categories, language categories, and speaker IDs as inputs, embedding them into the text encoder, duration predictor, and flow layers. OpenVoice followed the standard training procedure provided by the original authors of VITS. After training, the model is capable of changing accents and languages, and reading input text with various emotions. OpenVoice also experimented with additional training data to learn rhythm, pauses, and intonation, which can be mastered in the same way as emotions.
Additionally, to train the tone color converter, OpenVoice created an MSML dataset containing 300,000 audio samples from 20,000 different individuals. Approximately 180,000 samples are in English, 60,000 in Chinese, and 60,000 in Japanese.
The training objectives for the tone color converter are twofold: firstly, OpenVoice requires the encoder-decoder to produce natural sound, supervised by the original waveform’s Mel-spectrogram loss and HiFi-GAN loss. Secondly, OpenVoice demands that the flow layers eliminate as much tone color information as possible from the audio features.
During training, the text of each audio sample is converted into a sequence of International Phonetic Alphabet (IPA) phonemes, each represented by a learnable vector embedding. These vector embeddings are processed through a transformer encoder to generate feature representations of the text content. OpenVoice uses dynamic time warping or monotonic alignment techniques to align text features with audio features and minimizes the KL divergence between them. Since the text features do not contain tone color information, this method encourages the flow layers to remove tone color information from their output. The output of the flow layers is influenced by the tone color information in the tone color encoder, which helps identify and eliminate tone color information. The flow layers are invertible, and by conditioning them on new tone color information and running their inverse process, new tone color can be added to the feature representations, which are then decoded into waveforms containing the new tone color.
Key of OpenVoice
The success of OpenVoice is not only due to its reasonable framework design and algorithmic innovation but more importantly, its use of a large amount of data recorded in multiple languages, accents, and by multiple speakers, all precisely annotated. The importance of these data lies in:
1. Diversity and Coverage: The multi-language, multi-accent dataset ensures that OpenVoice can handle various language environments and accent features, giving it broader applicability and flexibility globally.
2. Accurate Emotion and Style Simulation: The dataset from multiple speakers provides a rich sample of voices, enabling OpenVoice to more accurately capture and simulate the unique vocal characteristics of different speakers, including emotions, rhythm, and intonation.
3. Enhanced Model Generalization: A large and diverse training dataset helps improve the model’s generalization ability, maintaining efficiency and accuracy when faced with new and unseen voice samples.
4. Reduced Bias and Error: Precisely annotated data ensures accuracy during training, helping to reduce bias and errors in the learning process, and improving the quality of the final output.
5. Support for Complex Functions: For instance, the multi-language and multi-accent data support OpenVoice in voice cloning, not only replicating the speaker’s voice characteristics but also seamlessly switching between different languages and accents.
These precisely annotated and diverse datasets are the cornerstone for OpenVoice to achieve its advanced functions and high performance, crucial for training efficient, accurate, and reliable voice synthesis models. For many research teams and companies, collecting and recording such data themselves is costly, hence the need for professional data companies to assist in collection and recording. DataOceanAI is one such company with rich experience in data collection and accumulation. Our company possesses a vast amount of data for multi-emotional, multi-language, multi-scenario voice synthesis and voice conversion. These data, recorded, cleaned, and annotated by a professional team, can be directly used to train large models for voice conversion and synthesis, with examples as follows:
– France French Female Synthesis Corpus
King-TTS-010 >>>Learn more
– American English Female Speech Synthesis Corpus
King-TTS-033 >>>Learn more
– Swedish Male Speech Synthesis Corpus
King-TTS-060 >>>Learn more
– Finnish Female Speech Synthesis Corpus
King-TTS-075 >>>Learn more
References
Qin, Zengyi, Wenliang Zhao, Xumin Yu, and Xin Sun. “OpenVoice: Versatile Instant Voice Cloning.” arXiv preprint arXiv:2312.01479 (2023).






