




Recently, one of the three major AI image generation giants, Midjourney, unveiled its blockbuster image generation model, Midjourney V6, just before Christmas.

Midjourney V6 is an exciting image generation model with powerful creativity and generation effects. This version brings more details and realism through upgrades, earning high praise from users. With Midjourney V6, users can easily generate realistic images and artistic works, offering them a completely new experience. This version represents a significant upgrade from its predecessor, enhancing features related to understanding, image coherence, and model knowledge.
Currently, Midjourney V6 is available on Discord. Users can easily switch to this new version by selecting V6 from the dropdown menu under /settings or by entering the –v 6 in the chat.
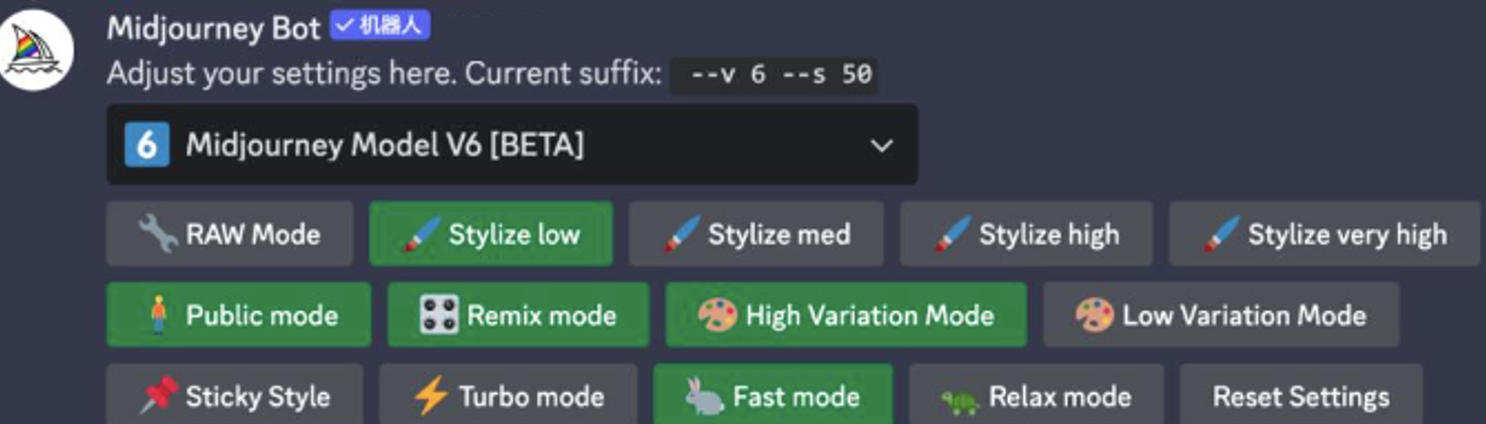
Founder David Holz posted information about V6 on Discord, stating that V6 is the team’s third model trained from scratch over a period of 9 months. In summary, V6 has undergone five major upgrades:
• More accurate and longer responses
• Improved coherence and model knowledge
• Optimized image generation and remixing
• Added basic text drawing functionality
• Enhanced amplifier functionality with “subtle” and “creative” modes, doubling the resolution【Image】
Pictures generated from Midjourney V6
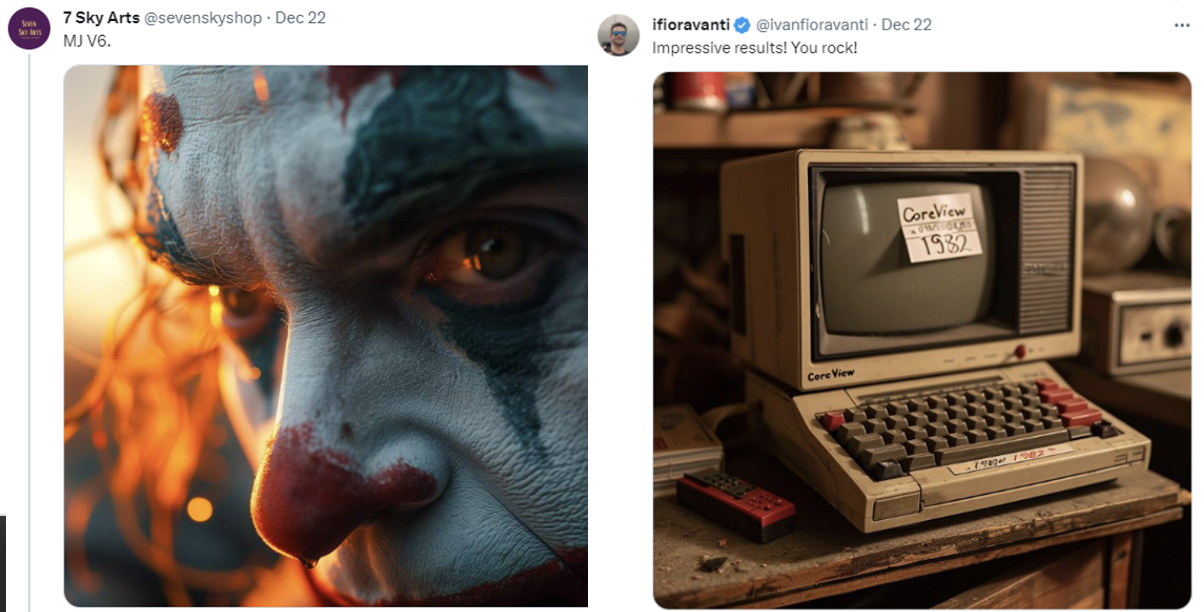
From Twitter and Discord
In terms of image quality, Midjourney V6 has seen significant improvement compared to its predecessors. From the images generated by users, it is evident that V6 excels in texture, lighting effects, and the authenticity of structures. Additionally, there are improvements in composition and color representation. Apart from the notable enhancement in image quality, Midjourney V6 can more accurately understand user instructions, generating high-definition images that better align with expected scenes.
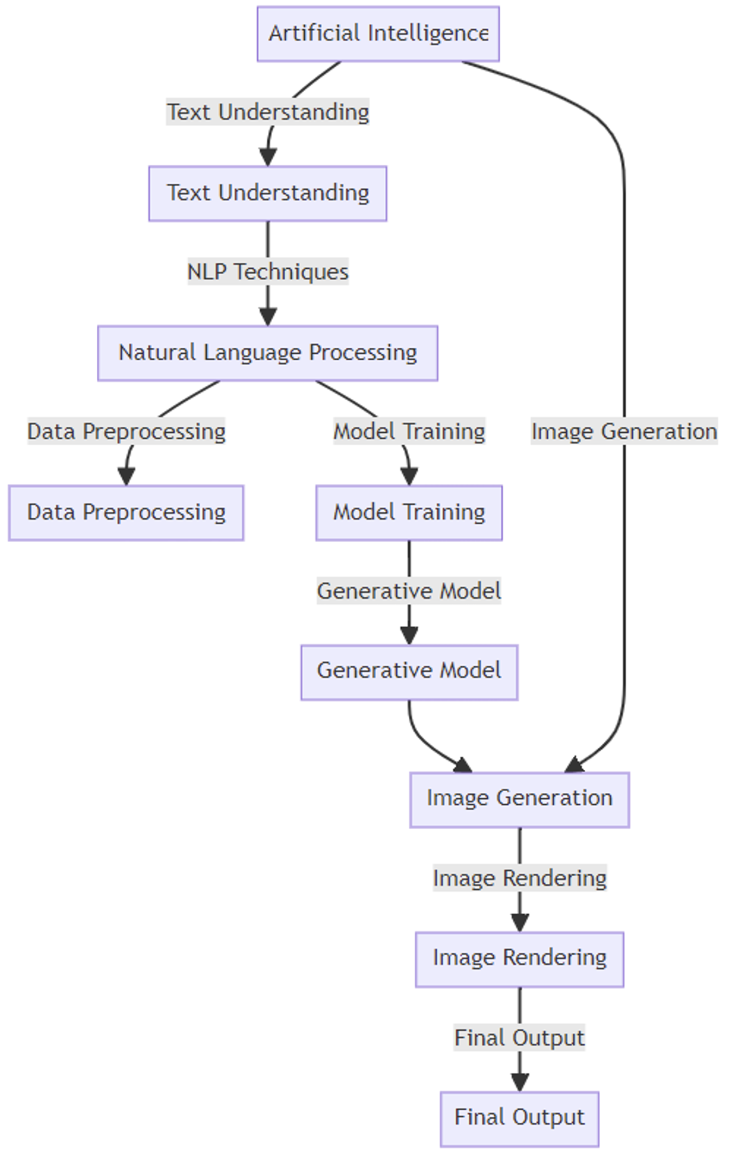
Text-to-Image Synthesis Technology
The framework of text-to-image synthesis technology is illustrated in the diagram below. In this framework, artificial intelligence (AI) technology is employed to understand text and generate images. The process involves text understanding, which encompasses natural language processing (NLP), including data preprocessing and model training. Subsequently, a generation model is used for image synthesis, ultimately producing the output image.
• Artificial Intelligence (AI): This is the core of the entire framework, involving the technologies of text understanding and image generation.
• Text Understanding (TU): This step represents the AI processing of text, serving as the starting point for the image generation process. Text understanding typically involves natural language processing technologies.
• Natural Language Processing (NLP): At this stage, the system utilizes NLP techniques to analyze and comprehend the input text, including language syntax, semantic analysis, and more.
• Data Preprocessing (DP): Before model training, data needs to undergo preprocessing. This may include steps such as text cleaning, standardization, feature extraction, etc.
• Model Training (MT): Preprocessed data is used to train the generation model. This process may involve machine learning and deep learning techniques.
• Generation Model (GM): The trained model used to generate visual content corresponding to the understood text.
• Image Synthesis (IS): This is the actual step of transforming text into images. The generation model creates visual content corresponding to the input text during this step.
• Output Image (OI): The final generated image is presented as output. These images are synthesized based on the input text content.
The entire process begins with text input, undergoes a series of processing and transformation steps, and concludes by generating images related to the input text content.
Text-to-Image Synthesis Dataset
The synthesis technology from text to image relies on large-scale paired datasets of text and images, which must be accurately annotated by professionals. To ensure that the synthesis model can generate high-quality results, these datasets not only need to be extensive and of high quality but must also cover a wide range of topics and scenes. This means that the data collection and annotation process must encompass diverse images and text content, enabling the model to learn and understand various complex visual and language information. Only with this comprehensive and meticulous data support can the model effectively transform textual descriptions into corresponding images to meet various creative and application requirements.
DataOceanAI is committed to contributing to this research direction by launching a comprehensive, large-scale, and professionally annotated dataset for image-text pairs.






