




Following the continuous promotion of its own models by Open AI to showcase their impressive effects, Google has finally launched the first shot in the open source of large models. Recently, Google introduced the Gemma series, a globally powerful and lightweight open-source large model. Gemma adopts the same technology as Gemini and belongs to the lite version of Gemini.
According to Google’s official introduction, Gemma is a large language model, unlike Gemini, which is a multimodal model. It is built on the same technology as Gemini, emphasizing open source and lightweight, and is available for free with open-source model weights, allowing commercial use. This undoubtedly lowers the threshold for AI entry and is a benefit to many small and medium-sized company.

The currently released Gemma series includes two versions: Gemma 2B (2 billion parameters) and Gemma 7B (7 billion parameters). Both versions offer pre-trained versions and variants that can be optimized through instructions. It is worth noting that Gemma 2B can even run directly on a laptop.
Technical Report
Model
Like Gemini, Gemma is built upon the foundation of the latest advancements in sequence modeling, neural network- d deep learning approaches, and training of large-scale models in distributed systems. Gemma also leverages Google’s rich history of open models and ecosystems, including Word2Vec, Transformer, BERT, T5, and T5X.
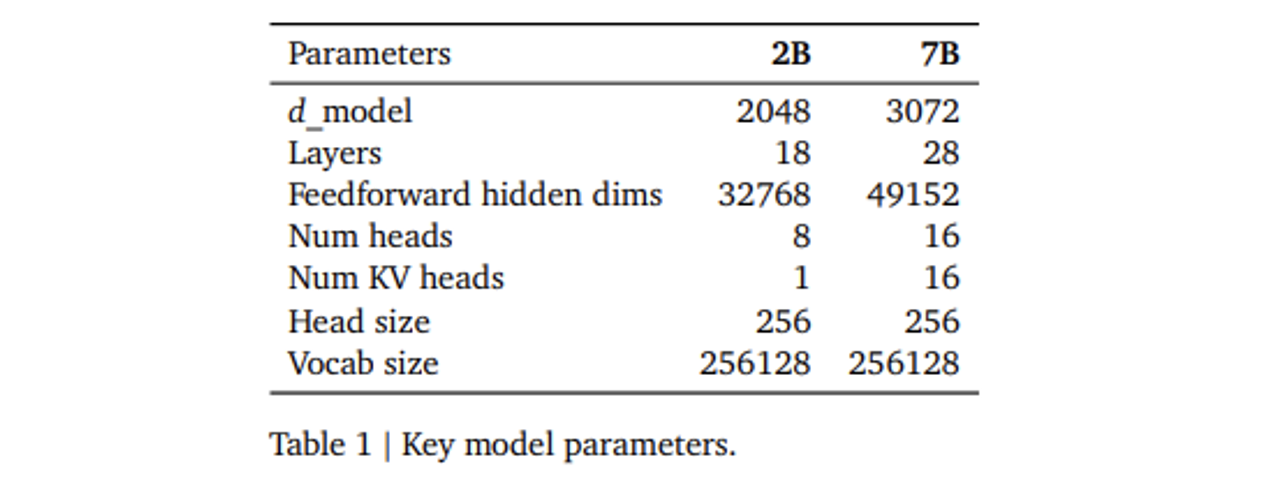
The Gemma model architecture is d on the Transformer decoder as its foundation, with core parameters outlined in Table 1. The models are trained with a context length of 8192 tokens. Gemma introduces several improvements:
• Multi-Query Attention: The 7B model utilizes multi-head attention, while the 2B checkpoints use multi-query attention (with num_kv_heads = 1). These choices are d on ablation studies, revealing improved performance of respective attention variants at different scales.
• RoPE dings: Instead of absolute positional dings, Gemma adopts rotary positional dings, and shares dings across inputs and outputs to reduce model size.
• GeGLU Activations: Replacing the standard ReLU activation function with the GeGLU activation function.
• Normalization Location: Both input and output of each Transformer sub- are normalized, contrary to the standard practice of normalizing only one. Gemma employs RMSNorm as the normalization .
Infrustration
Gemma utilizes TPUv5e for training, configured in a 2D torus structure of 16×16 chips per pod, with each pod containing 256 chips. For the 7B model, Gemma trains across 16 pods, totaling 4096 TPUv5e. For the 2B model pre-training, Gemma spans 2 pods, totaling 512 TPUv5e. Within a single pod, Gemma employs 16-way model sharding and 16-way data replication for training the 7B model, while for the 2B model, Gemma uses only 256-way data replication. The optimizer state is further partitioned using techniques similar to ZeRO-3, and beyond a pod, Gemma performs data replication reduction over the data-center network, utilizing the Pathways approach. Additionally, Gemma simplifies the development process by leveraging the “single controller” programming paradigm of Jax and Pathways, enabling a single Python process to orchestrate the entire training process. Gemma also utilizes the GSPMD partitioner for training step computation and the MegaScale XLA compiler.
Training Data
Gemma’s 2B and 7B models were trained on 2T and 6T tokens, respectively, sourced primarily from English web s, mathematics, and code. Unlike Gemini, these models are not multimodal and have not been trained for state-of-the-art performance on multilingual tasks. Google employed a subset of Gemini’s SentencePiece tokenizer to ensure compatibility. This tokenizer splits digits, retains extra whitespace, and relies on byte-level encoding for unknown tokens, aligning with techniques used in both Chowdhery et al. (2022) and the Gemini Team (2023). The vocabulary size is 256k tokens.
Google filtered the pre-training dataset using heuristic methods and model- d classifiers to mitigate unnecessary or unsafe language and remove certain personal information and other sensitive data. Additionally, all evaluation sets were filtered out from the pre-training data mixture, targeted contamination analyses were run to check for evaluation set leakage, and the risk of recitation was reduced by minimizing the proliferation of sensitive outputs. The final data mixture was determined through a series of ablations on both the 2B and 7B models. Similar to the approach advocated by the Gemini Team (2023), training was staged to alter the corpus mixture throughout training to increase the weight of relevant, high-quality data towards the end of training.
Google performed supervised fine-tuning (SFT) on Gemma’s 2B and 7B models, utilizing a mixture of text-only, English-only synthetic, and human-generated -response pairs, and fine-tuned them through reinforcement learning from human feedback (RLHF). The reward model was trained on token-only English preference data, while the strategy was d on a set of high-quality s. Experimental findings highlighted the importance of both stages in improving the model output performance in downstream automatic evaluation and human preference assessment.
Mixed data was selected for supervised fine-tuning d on language model- d comparative evaluations. Given a set of retained s, responses were generated from the test model, responses generated from the line model using the same s, and then shuffled randomly. Larger, higher-performance models were then asked to express preferences between the two responses. Different sets were constructed to highlight specific abilities such as following instructions, factuality, creativity, and safety. Various automatic language model assessors were employed using multiple techniques such as chain s and using scoring criteria and constitutions to align with human preferences.
During the use of synthetic data, several filtering stages were run to remove examples displaying specific personal information, unsafe or toxic model outputs, mistaken self-identification data, or duplicated examples. Following the approach of Gemini, experiments revealed that including subsets of data encouraging better contextual attribution, avoidance, and refusal to minimize hallucinations could improve the performance of multiple factuality metrics without reducing the model’s performance on other metrics. The final data mixture and supervised fine-tuning recipe, including adjusted hyperparameters, were selected d on enhancing helpfulness while minimizing model harms related to safety and hallucinations.
Data in Target Domain
Compared to large-scale models like ChatGPT and Gemini, Gemma is more suitable for various small-scale applications such as chatbots for customer service. However, through Gemma’s technical ation, we understand that the majority of its training data is primarily in English. For some downstream tasks and specific application scenarios like financial customer service, hospital navigation systems, and smart driving systems, further fine-tuning may be necessary. This requires specialized domain-specific data for model adaptation.
In this regard, DataOceanAI, as a professional training data company, possesses expertise in linguistics, and abundant domain-specific data annotated by industry professionals. These datasets can be utilized for fine-tuning and transferring existing large-scale models on the market, thereby enhancing the models’ capabilities in specific domains. DataOceanAI’s training data services provide valuable support for the deployment of models, offering solutions for various application scenarios’ real-world requirements.
Reference
Gemma: Open Models d on Gemini Research and Technology
Dataocean AI empowers enterprises to develop more diverse and high-quality models and products to meet the extensive needs of global users. Contact us for more datasets.
King-ASR-127 American English Conversational Speech Recognition Corpus (Multi-Channel) >>>Learn More
King-ASR-401 American English Conversational Speech Recognition Corpus (Mobile)
King-ASR-951 Chinese-English Mixed Speech Recognition Corpus >>>Learn More






