




The term “Giga” originates from “gigantic,” reflecting the vast audio resources available on the internet. However, the quality of these audio resources varies significantly, and high-quality audio-text pairs are particularly scarce and expensive to annotate, especially for low-resource languages.
GigaSpeech, a highly successful open-source English dataset, addresses this issue by providing thousands of hours of high-quality, text-annotated speech data sourced from YouTube and Podcasts. This dataset has garnered significant attention and widespread application. Despite these advancements, the multilingual field still faces challenges such as poor speech recognition performance and a lack of high-quality annotated data.
To tackle these issues, we propose a new paradigm that leverages in-the-wild unannotated audio to construct large-scale, high-quality speech recognition datasets. This approach has led to the creation of GigaSpeech 2, a massive, multi-domain, multilingual speech recognition dataset designed for real-world applications.
Models trained on the GigaSpeech 2 dataset have achieved performance on par with commercial speech recognition services for three Southeast Asian languages: Thai, Indonesian, and Vietnamese. Driven by the belief that technology should benefit everyone, we are committed to open-sourcing high-quality speech recognition datasets and models, thereby promoting multilingual cultural communication.

1. Overview
GigaSpeech 2 is a collaborative effort developed by the SJTU Cross Media Language Intelligence Lab (X-LANCE) at Shanghai Jiao Tong University, SpeechColab, The Chinese University of Hong Kong, the Speech and Audio Technology Lab (SATLab) at Tsinghua University, Peng Cheng Laboratory, Dataocean AI, AISpeech, Birch AI, and Seasalt AI.
GigaSpeech 2 is an ever-expanding, large-scale, multi-domain, and multilingual speech recognition corpus designed to promote research and development in low-resource language speech recognition. GigaSpeech 2 raw contains 30,000 hours of automatically transcribed audio, covering Thai, Indonesian, and Vietnamese. After multiple rounds of refinement and iteration, GigaSpeech 2 refined offers 10,000 hours of Thai, 6,000 hours of Indonesian, and 6,000 hours of Vietnamese. We have also open-sourced multilingual speech recognition models trained on the GigaSpeech 2 data, achieving performance comparable to commercial speech recognition services.
2. Dataset Construction
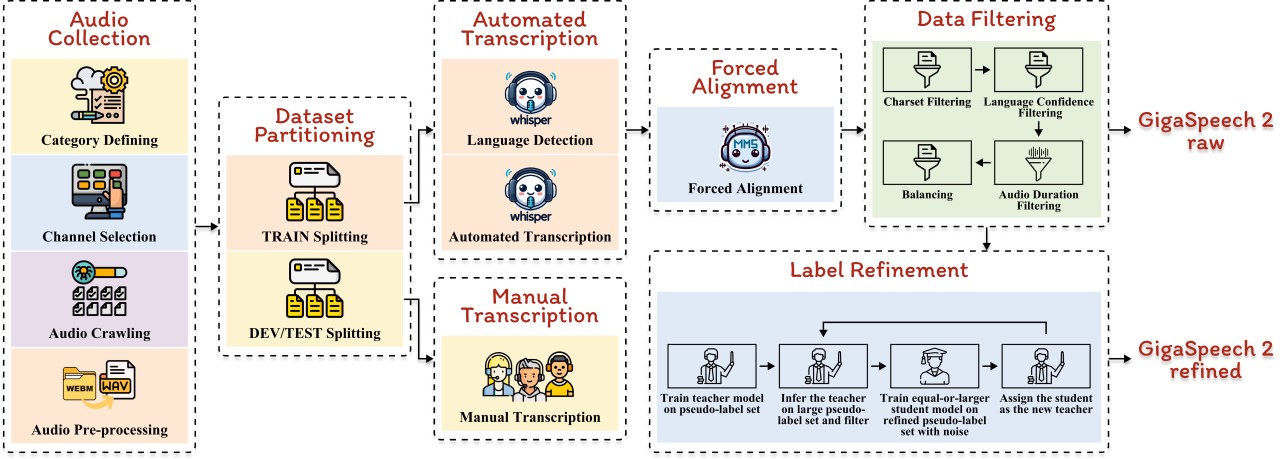
The construction process of GigaSpeech 2 has also been open-sourced. This is an automated process for building large-scale speech recognition datasets from vast amounts of unannotated audio available on the internet. The automated process involves data crawling, transcription, alignment, and refinement. Initially, Whisper is used for preliminary transcription, followed by forced alignment with TorchAudio to produce GigaSpeech 2 raw through multi-dimensional filtering. The dataset is then refined iteratively using an improved Noisy Student Training (NST) method, enhancing the quality of pseudo-labels through repeated iterations, ultimately resulting in GigaSpeech 2 refined.
GigaSpeech 2 encompasses a wide range of thematic domains, including agriculture, art, business, climate, culture, economics, education, entertainment, health, history, literature, music, politics, relationships, shopping, society, sports, technology, and travel. Additionally, it covers various content formats such as audiobooks, documentaries, lectures, monologues, movies and TV shows, news, interviews, and video blogs.
3. Training Set Details
GigaSpeech 2 offers a comprehensive and diverse training set, which is meticulously designed to support the development of robust and high-performing speech recognition models. The training set details are as follows:
| Thai | Indonesian | Vietnamese | |
| GigaSpeech 2 raw | 12901.8h | 8112.9h | 7324.0h |
| GigaSpeech 2 refined | 10262.0h | 5714.0h | 6039.0h |
4. Development and Test Set Details
The development and test sets of GigaSpeech 2 have been manually annotated by professionals from Dataocean AI. The duration details of these sets are provided in the table below:
| Thai | Indonesian | Vietnamese | |
| GigaSpeech 2 TEST | 10.0h | 10.0h | 10.2h |
| GigaSpeech 2 DEV | 10.0h | 10.0h | 11.0h |
The following diagram illustrates the details of theme and content distribution. The outer circle represents the thematic domains, while the inner circle represents the content formats:
| Thai | Indonesian | Vietnamese | |
| GigaSpeech 2 raw | 12901.8h | 8112.9h | 7324.0h |
| GigaSpeech 2 refined | 10262.0h | 5714.0h | 6039.0h |
The following diagram illustrates the details of theme and content distribution. The outer circle represents the thematic domains, while the inner circle represents the content formats:
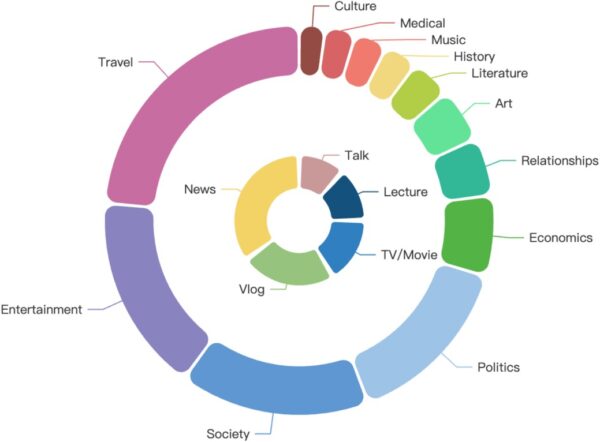
Thai
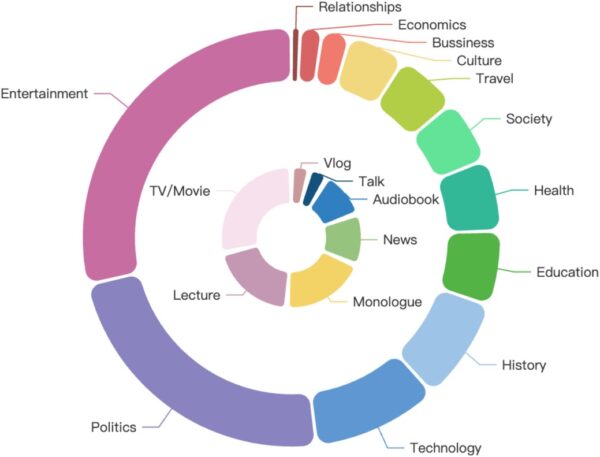
Indonesian
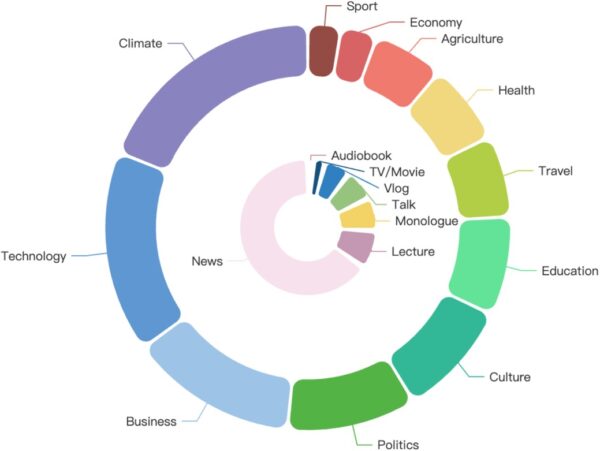
Vietnamese
5. Experimental Results
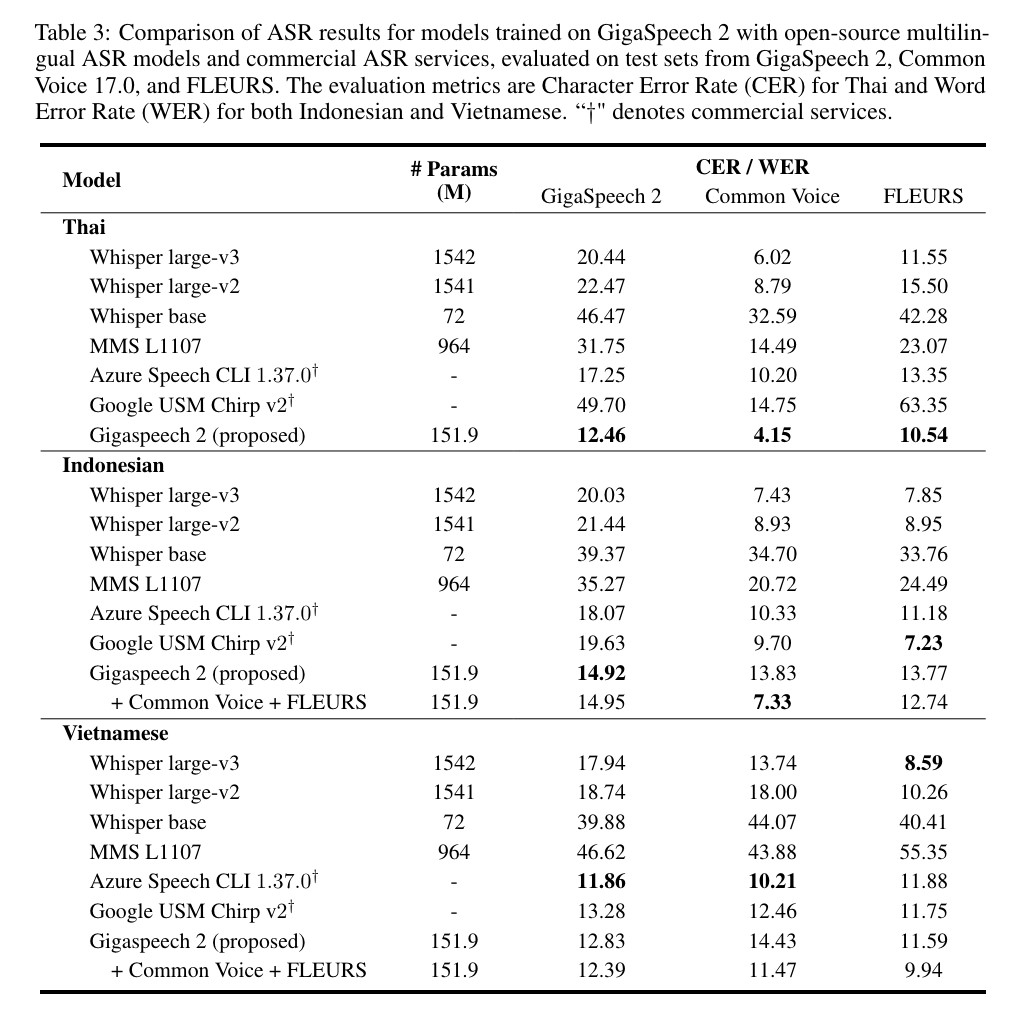
We conducted a comparative evaluation of speech recognition models trained on the GigaSpeech 2 dataset against industry-leading models, including OpenAI Whisper (large-v3, large-v2, base), Meta MMS L1107, Azure Speech CLI 1.37.0, and Google USM Chirp v2. The comparison was carried out in Thai, Indonesian, and Vietnamese languages. Performance evaluation was based on three test sets: GigaSpeech 2, Common Voice 17.0, and FLEURS, using Character Error Rate (CER) or Word Error Rate (WER) as metrics. The results indicate:
-
Thai: Our model demonstrated exceptional performance, surpassing all competitors, including commercial interfaces from Microsoft and Google. Notably, our model achieved this significant result while having only one-tenth the number of parameters compared to Whisper large-v3.
-
Indonesian and Vietnamese: Our system exhibited competitive performance compared to existing baseline models in both Indonesian and Vietnamese languages.
6. Leaderboard
To facilitate usage and track the latest technological advancements, GigaSpeech 2 provides baseline training scripts based on mainstream speech recognition frameworks and maintains an open leaderboard. Currently, systems such as Icefall and ESPNet are included, with further updates and improvements planned for the future.
| Tool | System | Thai language TEST CER |
Indonesian TEST WER |
Vietnamese TEST WER |
| Icefall | Zipformer/ Stateless pruned RNN-T | 12.46 | 14.92 | 12.83 |
| ESPNet | Conformer /Transformer CTC/AED | 13.70 | 15.50 | 15.60 |
7. Resource Links
The GigaSpeech 2 dataset is now available for download: https://huggingface.co/datasets/speechcolab/gigaspeech2
The automated process for constructing large-scale speech recognition datasets is available at: https://github.com/SpeechColab/GigaSpeech2
The preprint paper is available at: https://arxiv.org/pdf/2406.11546






