




Recently, OpenAI’s GPT Realtime and Google’s Gemini 2.5 made headlines, bringing voice assistants into a new era of “true real-time conversation.” You speak, and the AI replies instantly; even better, if the AI is mid-response, you can interrupt at any moment—and it handles it naturally, without awkward pauses. This is the closest AI has come to human-like “interruptible” dialogue.
This advancement is attributed to full-duplex voice interaction models; it overturns the traditional half-duplex paradigm of ‘speak-then-wait’ interactions. Instead, speaking and listening now happen simultaneously. With perception modules capturing subtle details of your voice in real time, the model can decide within milliseconds whether to continue responding, pause, or yield the floor. Relying on adaptive strategies, the dialogue becomes more natural, with reduced latency and accelerated interaction. Empirical results indicate that response delays are reduced by more than a factor of three, with over 50% of conversations reaching the vocalization stage in under 500 milliseconds.
OpenAI’s newly released GPT Realtime speech model takes this even further. Beyond handling interruptions and corrections seamlessly, it can also pick up non-verbal cues such as laughter and pauses, and even switch languages mid-conversation without missing a beat. Around the same time, social platform Soul unveiled its own end-to-end full-duplex conversational model, breaking away from the rigid “turn-taking” structure and giving AI the autonomy to control the rhythm of dialogue.

Tech Deep Dive: What Is Full-Duplex Voice Interaction?
Put simply, full-duplex voice interaction allows a system to process and respond to speech input while listening simultaneously—just as naturally as humans do in face-to-face conversation. Unlike the traditional half-duplex mode, where one must finish speaking before receiving a reply, full-duplex enables:
- Real-time interruption: correct or modify instructions at any moment
- Simultaneous listening and speaking: respond without waiting for the other party to finish
- Noise rejection: intelligently filter out background sounds and non-command speech
This technology allows smart speakers to accept commands while playing music, enables in-car assistants to handle incoming calls while providing navigation, and empowers conferencing systems to separate multiple speakers’ voices in real time while delivering instant translation.
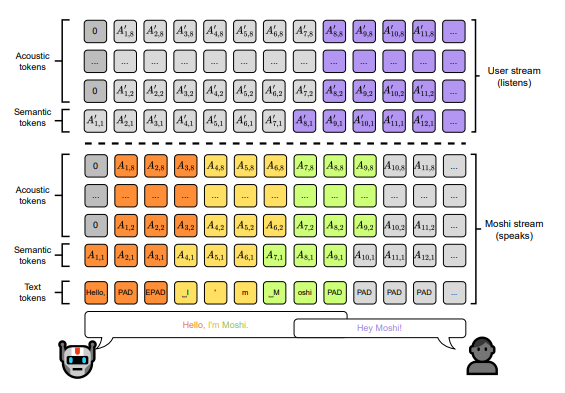
Making these models converse as flexibly as humans requires more than just algorithms— “data” is the real cornerstone. Interruptions, feedback cues (such as “uh-huh” or “right”), overlapping speech, natural pauses, and colloquial expressions all demand authentic, diverse, and accurately labeled dialogue samples. Only with such data can models learn when to respond, what to say, and how to reply naturally.
This is especially critical for full-duplex voice models, which rely on large amounts of precisely annotated speech data to learn:
- Multi-speaker separation: identify and separate overlapping voice signals
- Contextual understanding: capture conversational context and emotional dynamics
- Multilingual handling: adapt to different languages and dialects
- Paralinguistic cues: recognize laughter, sighs, pauses, and other non-verbal signals
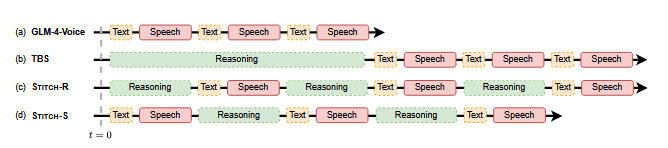
Currently, most speech training datasets consist of continuous recordings with complete conversational turns, lacking the naturally occurring, hard-to-model segments such as mid-utterance responses or interrupted speech. Even industry benchmark datasets have only recently been upgraded to support overlap handling, as seen in the Full-Duplex-Bench v1.5 standard. This benchmark specifically evaluates the quality and fluency of AI responses in scenarios involving user interruptions, background speech, and side-talk interruptions.
DataoceanAI Develops a 9,000-Hour Chinese Full-Duplex Speech Recognition Corpus
This full-duplex dataset features the following core strengths:
✅ Product Highlights:
- The dataset comprises approximately 10,000 speakers across different age groups, with balanced gender representation.
- Recorded via mobile devices, it includes rich pause annotations, colloquial expressions, and a character-level transcription accuracy of 97%.
✅ Diverse Scenarios:
- Covers a wide range of contexts, including casual conversations, family life, friend interactions, business meetings, AI assistants, and new energy scenarios such as electric vehicles and e-bikes.
✅ Precise Annotations Supporting Multiple Tasks:
- Each audio segment is professionally track-separated, with independent tracks for each speaker.
- Supports complex dialogue phenomena such as interrupted speech, overlapping turns, and two-person interactions, and includes:
- High-precision transcriptions (97% character-level accuracy)
- Speaker metadata (gender, age, regional accent)
- Timestamps, environment labels, and special scenario markers
- Paralinguistic cues (laughter, sighs, pauses, feedback words, etc.)
- Speech overlap and noise annotations
✅ Compliant and Commercially Ready:
- Strictly adheres to international standards (ISO/IEC 27001, ISO/IEC 27701:2019)
- Data collection and authorization are fully compliant, making it safe for commercial deployment without copyright concerns.
From GPT Realtime to Gemini 2.5, full-duplex interaction is the next-generation core competency for voice assistants. To achieve truly smooth, interruptible conversational experiences, your model must be trained on something no human trainer can replicate—the highly reliable 9,000-Hour Chinese Full-Duplex Speech Recognition Corpus. With it, your project can achieve GPT Realtime–level natural interactions, enabling AI to seamlessly interject and converse with human-like fluency.






