




Authors: Hugo Touvron, Louis Martin, Kevin Stone et.al
Affilications: GenAI, Meta
PDF: https://arxiv.org/pdf/2307.09288.pdf
Abstract
This paper explores the creation of Llama 2, a large-scale language model with 7 billion to 70 billion parameters. It focuses on refining Llama 2-Chat for practical use, claiming superiority over open-source chat models. The paper details fine-tuning, and security enhancements, and encourages community contribution. It addresses human evaluation biases, and delves into Llama 2’s capabilities, training, and computational challenges. Comparisons with models like BLOOM, Llama 1, Falcon, GPT-3, and Chinchilla are made. The upcoming release of Llama 2 and Llama 2-Chat (up to 70 billion parameters) for research and commercial use is outlined, along with security measures like data annotation, red team testing, and iterative assessments.
Introduction
The authors delve into the capabilities and training methods of large language models (LLMs). They highlight LLMs’ potential as adept AI assistants for intricate tasks that demand specialized knowledge, like programming and creative writing. These models, with intuitive chat interfaces, have been rapidly embraced by the public.
The training process is simple yet impressive. Autoregressive transformers are initially pretrained on vast amounts of self-supervised data and then fine-tuned using techniques like reinforcement learning with human feedback (RLHF) to align with human preferences. However, substantial computational requirements hinder LLM development.
The authors compare publicly released LLMs such as BLOOM, Llama 1, and Falcon to closed-source counterparts like GPT-3 and Chinchilla. While closed-source models excel due to fine-tuning, its costs and lack of transparency hamper AI alignment research.
Their contribution includes Llama 2 and Llama 2-Chat, LLMs with up to 70 billion parameters. Llama 2-Chat surpasses open-source models in utility and security benchmarks. They enhance security through data annotation, red team testing, and iterative evaluation.
- Llama 2, an updated version of Llama 1, uses new data, a larger pre-training corpus, and grouped query attention. Variants with 7B, 13B, and 70B parameters will be published.
- Llama 2-Chat, optimized for conversations, also comes in these variants. While these models aid research and commercial use, they require safety validation and adaptation for specific scenarios.
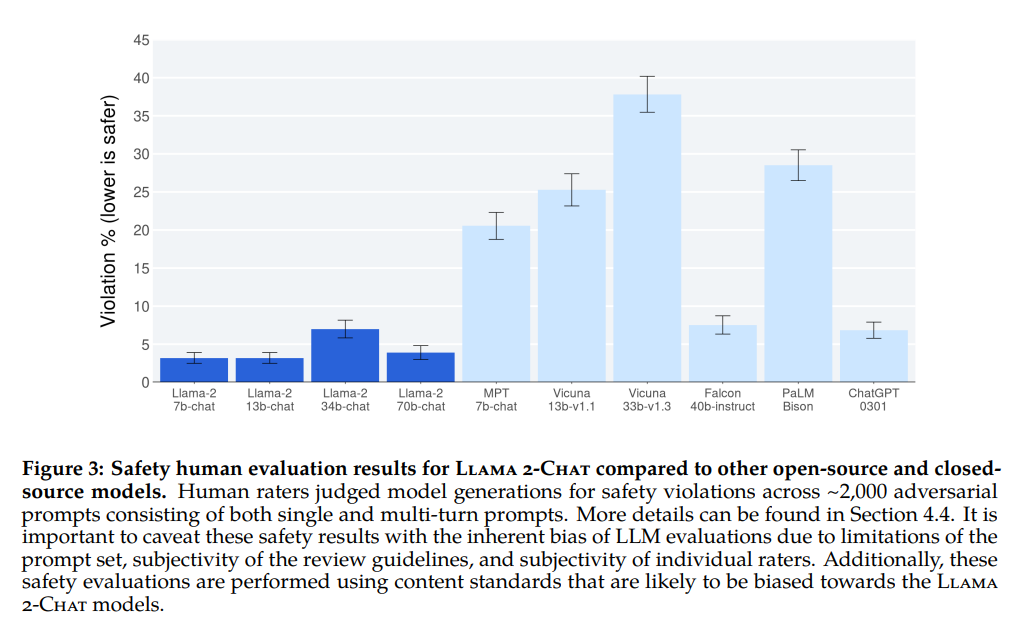
The above graph presents a comparison of security human evaluation outcomes between Llama 2-Chat and other open-source and closed-source models. Human evaluators assessed the safety violations of model-generated content based on around 2000 adversarial prompts, including both single-turn and multi-turn prompts. However, these safety evaluation results could be influenced by factors such as the prompt set, the subjectivity of evaluation guidelines, and individual evaluator bias, potentially favoring the Llama 2-Chat model.
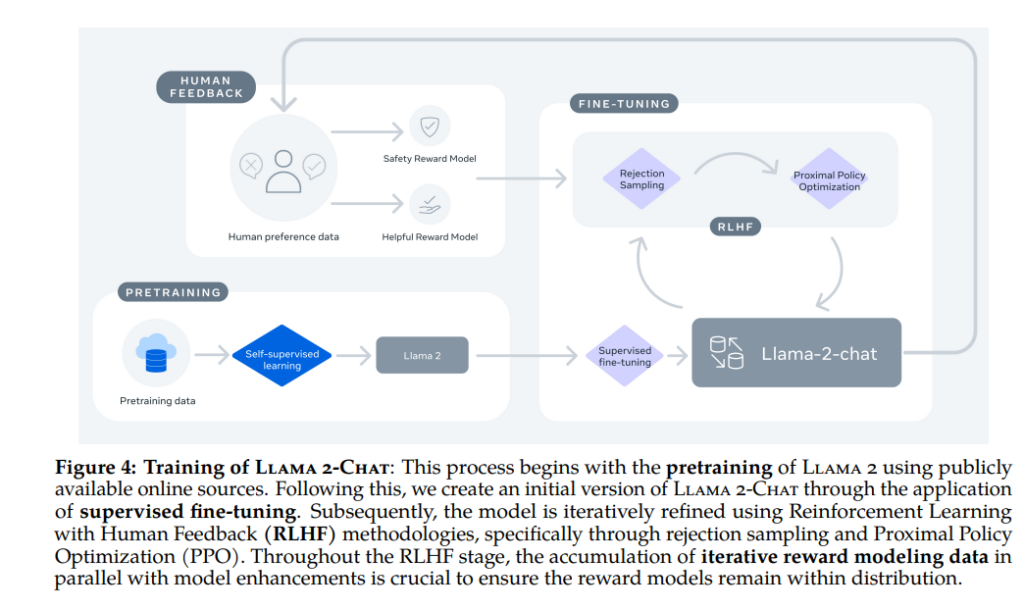
The diagram above illustrates the training process of Llama 2-Chat. The process commences with the pretraining of Llama 2 using publicly available online resources. Subsequently, the initial version of Llama 2-Chat is created through supervised fine-tuning. Then, employing Reinforcement Learning with Human Feedback (RLHF), including rejection sampling and Proximal Policy Optimization (PPO), the model undergoes iterative refinement. During the RLHF phase, the accumulation of iterated reward modeling data closely associates with model enhancement, ensuring the reward model remains within the distribution.
Pretraining
In the development of the new Llama 2 model family, the authors adopted a pre-training approach outlined by Touvron et al., leveraging an optimized autoregressive transformer with further refinements to enhance performance. Notably, these refinements encompassed more robust data cleansing, an updated data blend, expanded training with increased total labels, a doubling of context length, and the utilization of grouped query attention (GQA) to enhance inference reliability and scalability for larger models.
Regarding the training data, the Llama 2 model’s training corpus encompasses a blend of fresh data from publicly accessible sources, excluding data associated with Meta’s products or services. The authors took measures to exclude data from sites known to contain private personal information. The training process incorporated 2 trillion tokens, strategically oversampling realistic sources to bolster knowledge while minimizing distortions. The authors conducted diverse pre-training data assessments to enhance users’ comprehension of the model’s potential and limitations.
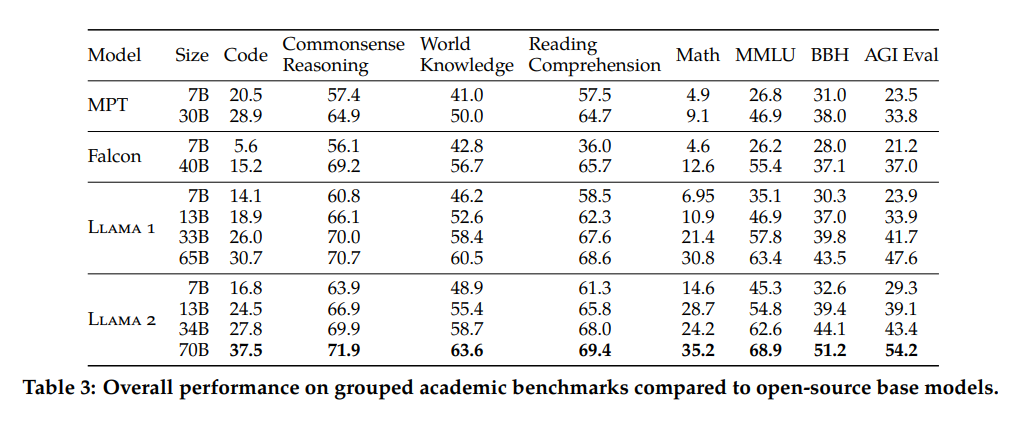
This section also reports on the evaluation of the Llama 2 pre-trained model. The authors benchmarked the model against Llama 1, MosaicML Pretrained Transformer (MPT), and Falcon models using standard academic benchmarks. These benchmarks encompass various domains, including commonsense reasoning, world knowledge, reading comprehension, mathematics, and popular aggregated benchmarks.
Table 3 presents an overview of the model’s performance across these benchmarks. Notably, security benchmarks are discussed in Section 4.1, while comprehensive results for individual benchmarks can be found in Section A.2.2. This comprehensive evaluation demonstrates the Llama 2 model’s efficacy across diverse tasks and domains.
Fine-tuning
Llama 2-Chat is the result of extensive research involving alignment techniques, guided tuning, and RLHF.
The Ghost Attention (GAtt) technique was introduced for controlling multi-turn dialog flow.
- Supervised Fine-Tuning (SFT)
- Quality focus: Emphasis on high-quality and diverse SFT data.
- Filtered millions of third-party examples, and incorporated fewer in-house annotations.
- Limited dataset (27,540 annotations) sufficient for high-quality outcomes.
- Data quality verification is crucial; the SFT model’s outputs are competitive with human annotations.
- Reinforcement Learning from Human Feedback (RLHF)
- Human preference data was collected for reward modeling through binary comparison.
- Annotators composed prompts, selected between model responses.
- Attention to utility and safety in annotation; large dataset (Meta Reward Modeling Data) compiled.
- Reward Modeling
- Reward models for utility and safety; initialized from pre-trained checkpoints.
- Binary ranking labels are transformed from human preference data.
- Data composition: New and existing datasets combined for training.
- Reward models outperform baselines including GPT-4.
- Iterative Fine-Tuning (RLHF)
- RLHF-V1 to RLHF-V5 iterations explored.
- Proximal Policy Optimization (PPO) and Rejection Sampling fine-tuning algorithms were used.
- A combined approach for enhanced model performance.
- Training details: Optimizer, learning rate, iterations, FSDP usage.
- System Message for Multi-Turn Consistency
- Reward models segmented for safety and helpfulness.
- The ghost Attention (GAtt) method was introduced to guide attention focus.
- GAtt maintains dialog consistency up to 20+ turns.
- The model’s superiority over ChatGPT in safety and helpfulness is indicated by RLHF results.
- Acknowledgment of human evaluation limitations.
Overall, Llama 2-Chat’s research involves fine-tuning, reward modeling, and iterative RLHF processes, as well as the innovative Ghost Attention technique to ensure control over multi-turn dialog. The model shows promising results in aligning with human preferences and safety.
Comparison Llama 2 with Llama 1
- The Difference in Technical Details:
In the Llama1 paper, a comprehensive explanation of the training data methodology facilitates the replication of the process. Conversely, the Llama 2 paper focuses more on outlining the methodology for model training, displaying lower data transparency. Llama1 consists of 67% publicly obtained data and 15% carefully selected data. Although the Llama2 paper lacks in-depth data details, the meta section highlights a 40% larger pretraining corpus compared to Llama1’s, likely with similar characteristics. With tech companies sharing fewer training details, distributed training gains significance, as internal training mitigates security risks and intellectual property leakage.
- Reasons behind Data Opacity:
Meta’s model releases encounter risks, particularly for companies with large user bases, due to regulatory scrutiny regarding data safety and compliance. Data transparency is restricted to prevent replication, as Llama1’s data exposure resulted in unauthorized copying. Ongoing lawsuits, like Sarah Silverman’s copyright case involving Llama1 data, contribute to data opacity. Many web-crawled data aren’t genuinely “publicly available” due to copyright or usage concerns, highlighting the evolving gap between public data perception and AI’s evolving needs. The involvement of data annotation firms like Surge and Scale adds to data opacity. Llama2 employs meticulously curated datasets, incurring significant expenses.
- Significance of Data Quality:
Llama2 enhances credibility by assigning greater importance to highly reliable data, bolstering model confidence. Thorough data cleaning is pivotal for precise text generation. The discussion about the continued increase in training data quantity arises alongside advances in data quality assessment and deduplication techniques. The relationship between pretraining data volume and Chinchilla Optimal raises questions, given Llama2’s data surpasses Chinchilla Optimal’s constraints. The trend of augmenting training data volume may persist with advancements in quality assessment and deduplication methods, potentially altering past quality definitions.
Conclusion: The Victors of the World Are Those Who Attain the Data
Drawing from the details shared earlier, it becomes evident that the remarkable advancement of Llama 2 over its predecessor, Llama 1, can be largely attributed to two key factors: the expansion of its dataset’s scope and the enhancement of data quality. By embracing a larger and more diverse dataset, Llama 2 gains a deeper understanding of nuances and contexts across various domains, contributing to its improved performance. Moreover, the heightened focus on data quality ensures that the model is exposed to reliable, accurate, and refined information during its training process, leading to more accurate and coherent outputs.
This scenario resonates with the age-old adage “he who possesses the data holds the power.” In the realm of AI and machine learning, this principle reigns supreme as the quality and quantity of data directly impact the capabilities and effectiveness of models. With a more substantial and refined dataset, Llama 2 has the upper hand in comprehending complexities and generating relevant and insightful responses. Thus, in the dynamic landscape of AI, the strength of a model undeniably rests in the richness and reliability of the data it is trained on.
Discussion
Across the global landscape, large-scale models have gained immense popularity within the realm of natural language processing. However, the realm of speech technology has yet to witness the full emergence of openly accessible and operationalized large models. Recognizing this gap, DataOcean stands ready to make a substantial contribution to the domain of expansive speech models.
Our company is committed to addressing this shortfall by introducing significant volumes of high-quality speech data. This extensive dataset encompasses various facets of speech technology, encompassing speech recognition, speech synthesis, and speaker-related data. Notably, the data is characterized by its substantial volume and exceptional quality, rendering it eminently suitable for both fine-tuning and pretraining purposes. A selection of illustrative examples is provided below.






