




In today’s field of AI, LLM are undoubtedly the most eye-catching aspect. However, the high training costs and lengthy training times serve as major bottlenecks for many enterprises in adopting large-scale models.
For large enterprises, the race is about developing their own LLM, while for smaller businesses, it’s about how to best apply existing LLM to their specific business domains to create profit. Accessing LLM, each domain has its own unique knowledge barriers and text and voice paradigms, and breaking through these barriers is a challenge faced by small and medium-sized enterprises.
In fact, regarding these barriers, as early as 2021, Lewis and others proposed a universal method for fine-tuning large RAG (Retrieval-Augmented Generation) models. This method uses pretrained seq2seq models as parametric memory and Wikipedia’s dense vector index as non-parametric memory (accessed via a neural network pretrained retriever). The working principle of this method can be summarized as follows:
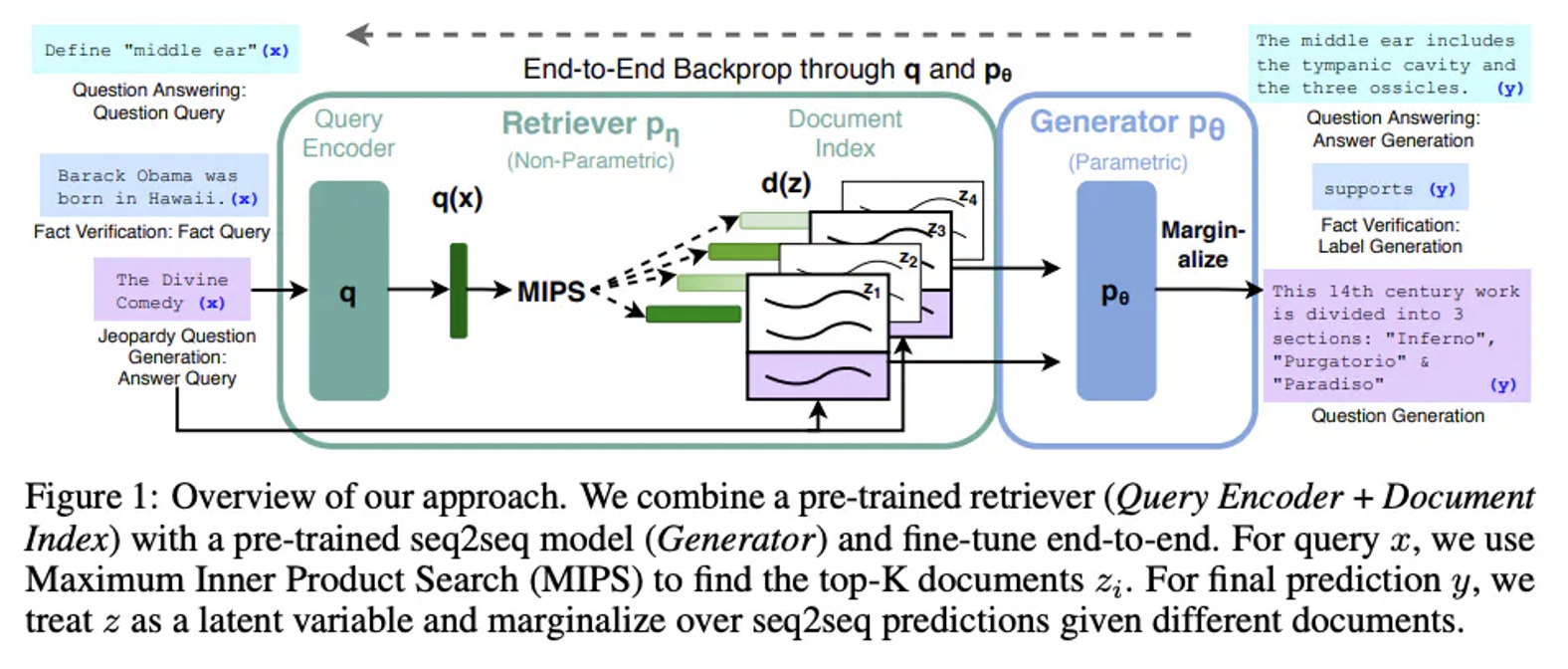
From: Lewis, Patrick, et al. “Retrieval-augmented generation for knowledge-intensive nlp tasks.” Advances in Neural Information Processing Systems 33 (2020): 9459-9474
RAG
RAG, short for Retrieval-Augmented Generation, is a model architecture for natural language processing tasks that combines the strengths of retrieval models and generation models.
The goal is to provide more accurate, fluent, and content-rich answers or generated content. The RAG model uniquely integrates these two aspects: retrieval and generation. It is not just a generation model but also a system that blends vector search with LLM generation capabilities.
Initially, RAG uses a vector model to transform questions and knowledge base content into vectors and selects the most relevant top-k s based on similarity. These s are then fed into a LLM to generate answers. This method not only improves the quality of the answers but crucially also provides interpretability to the model’s outputs.
The RAG model utilizes a retrieval model to gather relevant contextual information, enabling the generation model to create content based on a broader knowledge base. This not only enhances the richness and accuracy of the generated content but also reduces the likelihood of producing inaccurate or irrelevant material.
The RAG model combines the retrieved contextual information with the generation model, ensuring that the generated content accurately and coherently integrates the retrieved knowledge. This combination prevents the generation model from making guesses or producing inaccurate content when lacking sufficient context.
The RAG model allows the inclusion of multiple candidate answers or generated paragraphs from the retrieval model during the generation process, increasing the diversity of the results. This approach makes the generated content richer and more personalized, catering to the diverse needs of different users.
Vertical Domain Data
If the RAG model is applied to specific vertical domains, such as healthcare, law, or finance, training and optimizing it with domain-specific data can significantly enhance its performance in these areas.
Vertical domain data provides richer and more accurate domain-specific information, aiding the model in better understanding and responding to queries related to that field. Both LLM for voice and text need to be adapted to specific application scenarios based on the data of those specific scenes.
Collecting and organizing high-quality training data is crucial for developing excellent models. The data must be representative, diverse, and cover all aspects of the model’s application. Additionally, the quality and accuracy of the data need to be ensured, which can be achieved through data cleaning and labeling.
DataOceanAI provides a wealth of vertical domain data collection, including various languages and scenarios such as customer service, live broadcasting, and dialect voice databases. These are available for use in vertical domain models for RAG or fine-tuning and adaptation, thereby enhancing the accuracy and robustness of LLM in vertical domains. This includes their various language and scenario-based speech recognition databases:
King-ASR-914 American English Conversational Speech Recognition Corpus (Mobile)
Cell phone recordings of call center conversations on topics such as banking, healthcare, insurance, retail, telecommunications, and travel. Includes 102 people, 112.3 hours of data.
King-ASR-835 Japanese Business Meeting Conversational Speech Recognition Corpus (Mobile)
Recorded in groups of three people in a simulated meeting on how to solve the problem of rapidly decreasing game users. Includes 300 people and 112.87 hours of data.
King-TTS-174 Standard Arabic Female Speech Synthesis Corpus(Virtual Talk) >>>Learn More
Includes Standard Arabic, Gulf Arabic, Egyptian Arabic, Mixed English and other accents, with a variety of text types including news, life, travel, science and other scenes, 22.89 hours of data.
King-TTS-012 Germany German Male Speech Synthesis Corpus >>>Learn More
Including science and technology, education, games, beauty, diet, movie and television, news, life and other fields, 5.31 hours of data.






