




Overview
Building pre-trained language models (PLMs) with more parameters using large-scale training data significantly enhances the performance of downstream tasks. Taking the GPT-3 model trained by OpenAI as an example, with 175 billion parameters and 570GB of English training data, downstream applications can be developed with minimal samples. However, there is a shortage of Chinese corpora supporting large-scale Chinese PLMs. This paper introduces a super large-scale Chinese corpus, WuDaoCorpora, containing about 3TB of training data and 1.08 trillion Chinese characters. The authors also release the version of WuDaoCorpora, consisting of approximately 200GB of training data and 72 billion Chinese characters. As a benchmark, they train a Transformer-XL model with 3 billion parameters on the version to evaluate the corpus’s effectiveness. The results demonstrate outstanding performance of models trained on this corpus in Chinese tasks.
Dataset Download : [WuDaoCorpora](https://data.wudaoai.cn)
GitHub : [Chinese-Transformer-XI](https://github.com/THUDM/Chinese-Transformer-XI)
Paper : [ScienceDirect Article](https://www.sciencedirect.com/science/article/pii/S2666651021000152)
Background
This study emphasizes the effectiveness of training pre-trained language models (PLMs) on large corpora to improve their ability to learn general language representations. Previous research indicates that fine-tuning PLMs can enhance downstream task performance and avoid training downstream task models from scratch. With the advancement of computing power and innovations in sparse training methods, supporting the growth of model scale becomes feasible. However, PLMs with more parameters necessitate more data for training.
As natural language processing (NLP) technologies rapidly advance, the construction of large-scale corpora becomes increasingly crucial. The quality of NLP models heavily relies on the scale of corpora used for training. In response to this demand, researchers have built the world’s largest Chinese corpus, WuDaoCorpora, consisting of 3TB of Chinese data primarily sourced from the web. This corpus excels in protecting personal information and reduces the risk of personal privacy leakage by removing sensitive information.
The construction of WuDaoCorpora focuses on removing personal privacy information from the data, thereby enhancing the model’s security. Ultimately, they build a Chinese PLM (transformer-XL) with 3 billion parameters d on WuDaoCorpora. In summary, the primary contributions of this study include constructing the world’s largest Chinese corpus, emphasizing the protection of personal privacy information, and open-sourcing the largest Chinese PLM, transformer-XL.
Dataset Introduction
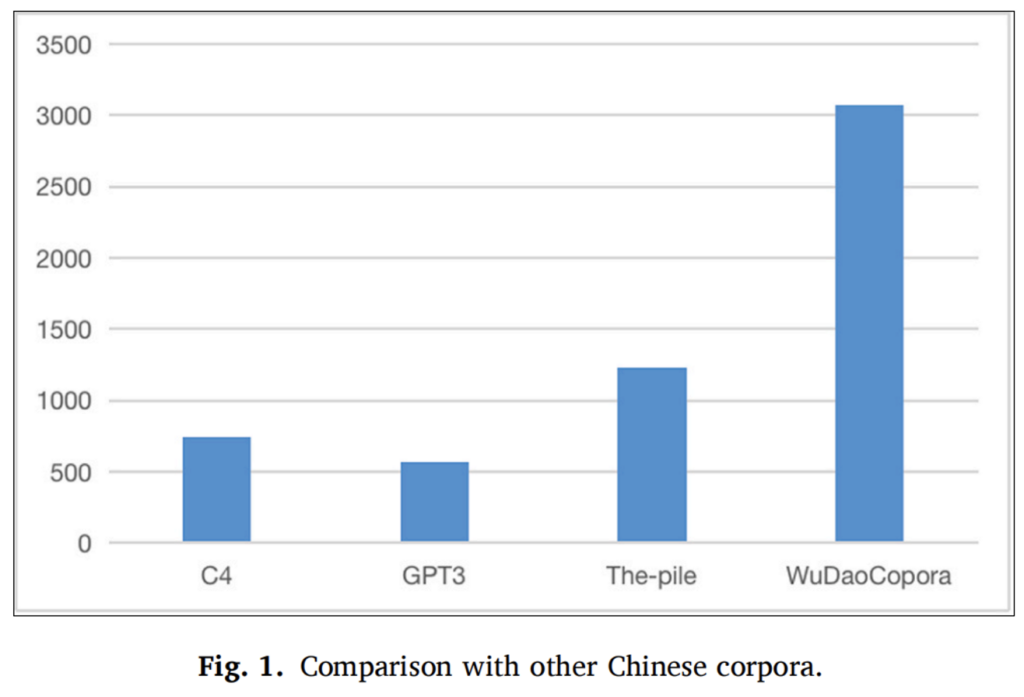
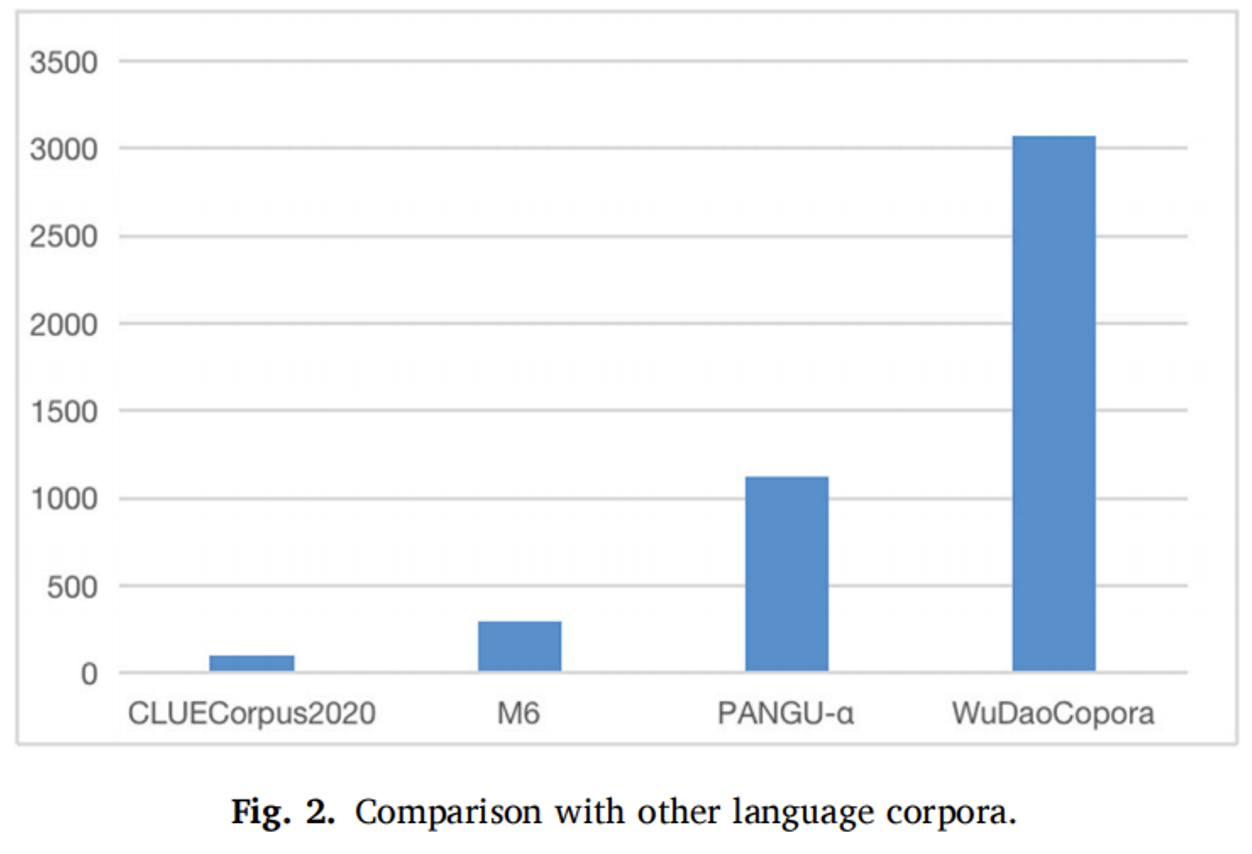
WuDaoCorpora is the first Chinese terabyte-level corpus directly designed for pre-trained language models (PLMs), showcasing an unprecedented scale. The magnitude of WuDaoCorpora is highlighted by comparing its scale with other Chinese corpora, as depicted in Figure 1, demonstrating its significant impact on the global scale, as shown in Figure 2.
The dataset is constructed from 3 billion raw web pages, undergoing extensive screening and processing, ultimately presented in a unified format of 3TB. Table 1 illustrates an example of the data.

The dataset construction process underwent meticulous steps to ensure quality:
• Before text extraction, the quality of each data source was assessed, excluding pages with text density below 70%.
• The simhash algorithm was used to identify and remove duplicate content resulting from common text reposting on web pages.
• Pages with insufficient content (fewer than 10 Chinese characters) were deemed unsuitable for language model training and excluded.
• To maintain a positive online environment, pages containing sensitive content (such as profanity or provocative comments) were excluded.
• To address privacy concerns, private information (e.g., ID numbers, phone numbers) was matched using regular s and removed from the dataset.
• Text was segmented using punctuation marks to remove incomplete sentences.
• Pages with high-frequency garbled words were filtered, and a decoding test was conducted for double-checking.
• Traditional characters were transformed into simplified characters to ensure consistency in character format.
• Abnormal symbols (such as emojis and logos) were removed to enhance text fluency.
• Pages containing more than ten successive non-Chinese characters were excluded to maintain the purity of the dataset.
• Useless web identifiers (HTML, CSS, ) were removed to enhance language model training.
• Spaces between two Chinese characters were deleted to normalize the corpus for improved coherence.
In summary, WuDaoCorpora not only addresses the scarcity of TB-level Chinese corpora for PLM training but also maintains high-quality standards through meticulous processing procedures.
Model
The model structure used in this paper is similar to the GPT2 model, adopting the decoder of the language model Transformer. The GPT2 model’s method for predicting words involves calculating the maximum likelihood of the conditional probability of present words given all historical information. The model in this paper is d on GPT2 with improvements in three aspects:
• Substituting the language model Transformer with Transformer-XL to handle longer token sequences.
• Reducing the model’s size to 512 and increasing the memory length by 256 units to process longer token sequences.
• Using the Zero Optimizer in DeepSpeed to train a large model without applying parallel training methods. With these improvements, a PLM with 3 billion parameters, currently the largest Chinese language PLM, was trained.
All models have 24 s, 16 heads, and a word ding dimension of 1024. Training details include a warm-up epoch of 0.01, batch size of 8, a maximum learning rate of 1.5 x10^-5, and a gradient clip set to 1. All models are trained on 64 NVIDIA Tesla V100 GPUs using a vocabulary of 13,088 Chinese characters.
Conclusion
This paper introduces a super large-scale Chinese corpus for PLMs, WuDaoCorpora, considered the largest Chinese corpus to date that can be directly used for PLM training. The paper filters data sources, screens web pages, and develops a complete data cleaning pipeline, with a focus on clearing privacy data to prevent personal privacy leakage at the data level. Additionally, each data point in WuDaoCorpora is annotated with a field tag, facilitating the extraction of data from the dataset for research in specific areas.
To enhance the cognitive abilities of PLMs, the authors plan to build the next version of WuDaoCorpora, which will include more dialogue corpus and common sense knowledge, laying a solid data foundation for improving PLMs’ cognitive abilities.
Reflection
This paper underscores the importance of comprehensive data cleaning, collection, accumulation, and annotation in building large-scale corpora. Clear data structures and reasonable annotations allow researchers to flexibly utilize this corpus for further studies and experiments. In the era of prevalent large models, data accumulation becomes a manifestation of a company’s core competitiveness. DataOceanA focuses on various aspects of the data field, including data collection, recording, annotation, and cleaning. We currently provide rich multimodal data resources such as voice, images, and videos, aiming to offer comprehensive data services for businesses. By establishing a data accumulation platform, we inject new energy into your enterprise, enhancing its core competitiveness. We provide customers with a one-stop data solution, supporting businesses to thrive in the digital age.
King-NLP-216 Chinese Multi-Turn Dialogue Corpus >>>Learn More






